
LLM性能最高60%提升!谷歌ICLR 2024力作:让大语言模型学会「图的语言」
LLM性能最高60%提升!谷歌ICLR 2024力作:让大语言模型学会「图的语言」图是组织信息的一种有用方式,但LLMs主要是在常规文本上训练的。谷歌团队找到一种将图转换为LLMs可以理解的格式的方法,显著提高LLMs在图形问题上超过60%的准确性。
来自主题: AI资讯
7668 点击 2024-03-27 17:52
 搜索
搜索
图是组织信息的一种有用方式,但LLMs主要是在常规文本上训练的。谷歌团队找到一种将图转换为LLMs可以理解的格式的方法,显著提高LLMs在图形问题上超过60%的准确性。

以脉冲神经网络(SNN)为代表的脑启发神经形态计算(neuromorphic computing)由于计算上的节能性质在最近几年受到了越来越多的关注 [1]。受启发于人脑中的生物神经元,神经形态计算通过模拟并行的存内计算、基于脉冲信号的事件驱动计算等生物特性,能够在不同于冯诺依曼架构的神经形态芯片上以低功耗实现神经网络计算。

Fast-DetectGPT 同时做到了高准确率、高速度、低成本、通用,扫清了实际应用的障碍!
Sora出世前,他们拿着一篇如今被ICLR 2024接收的论文,十分费劲地为投资人、求知者讲了大半年,却处处碰壁。

模型量化是模型压缩与加速中的一项关键技术,其将模型权重与激活值量化至低 bit,以允许模型占用更少的内存开销并加快推理速度。对于具有海量参数的大语言模型而言,模型量化显得更加重要。

在 2024 世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,
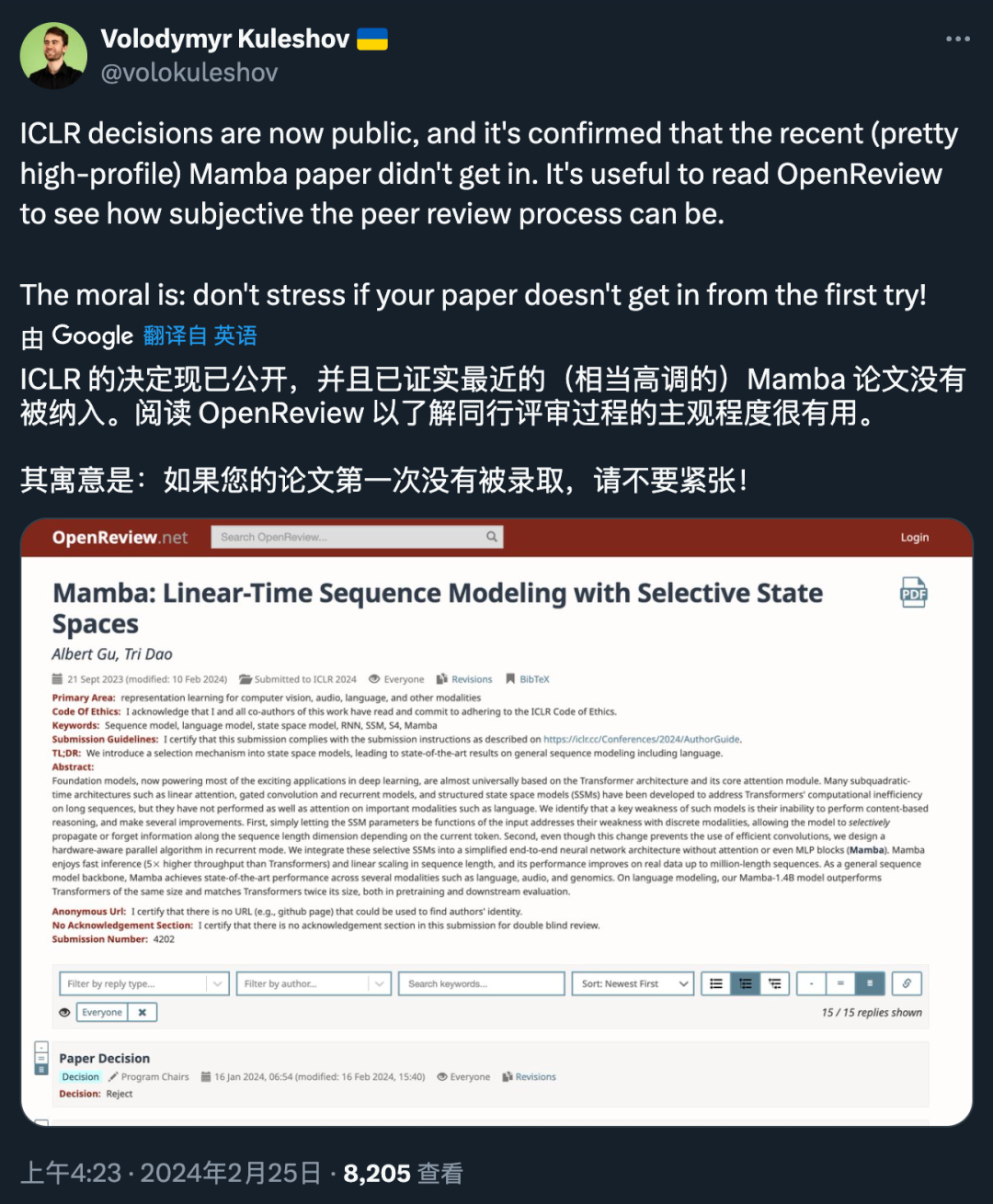
几天前,ICLR 2024 的最终接收结果出来了。

2 月 16 日,OpenAI Sora 的发布无疑标志着视频生成领域的一次重大突破。Sora 基于 Diffusion Transformer 架构,和市面上大部分主流方法(由 2D Stable Diffusion 扩展)并不相同。

单图 3D 说话人视频合成 (One-shot 3D Talking Face Generation) 可以被视作解决这一难题的下一代虚拟人技术。它旨在从单张图片中重建出目标人的三维化身 (3D Avatar)
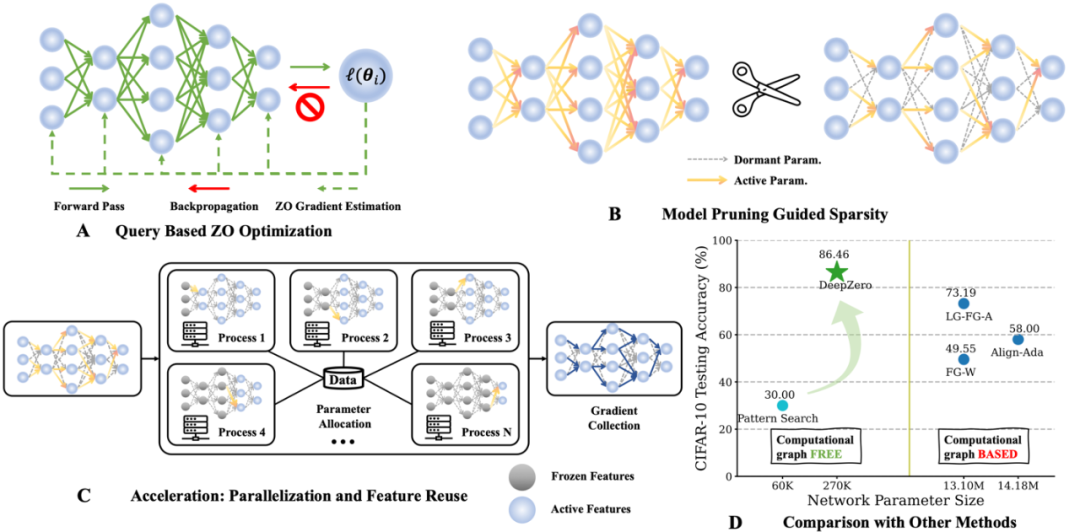
今天介绍一篇密歇根州立大学 (Michigan State University) 和劳伦斯・利弗莫尔国家实验室(Lawrence Livermore National Laboratory)的一篇关于零阶优化深度学习框架的文章 ,本文被 ICLR 2024 接收,代码已开源。